Section 12: K-Means Clustering
So far we have done supervised learning. The remaining sections will be on unsupervised learning. Below is a quick guide on how to pick the estimator:
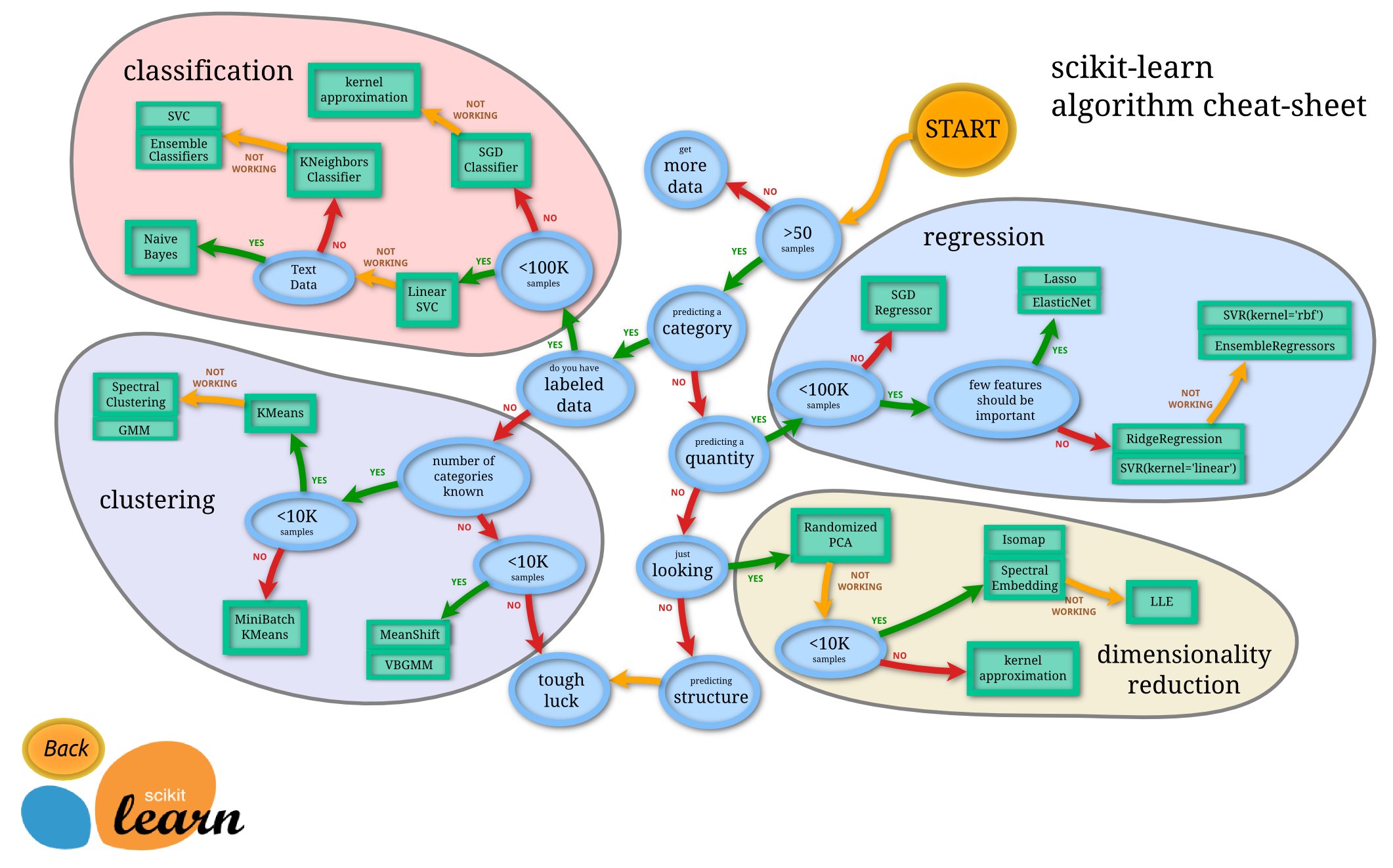 Source: scikit-learn
Source: scikit-learn
Unsupervised Learning: (1) Clustering: Using features, group together data rows into distinct clusters (2) Dimensionality Reduction: Using features, discover how to combine and reduce into fewer components
Supervised learning's performance metrics (RMSE or Accuracy) will not apply for unsupervised learning.
References:
- An Introduction to Statistical Learning (Download free pdf)
- Jose Portilla's 2021 Python for Machine Learning & Data Science Masterclass